- Node
- Python
To do this, you can use the
makeC1Response function to create a c1Response object, and then use the writeCustomMarkdown method to write the custom response to
the response object:1
Create a c1Response object
Use the
makeC1Response function to create a c1Response object by importing it from the @thesysai/genui-sdk package, and start writing the LLM response
content to this object:app/api/chat/route.ts
import { NextRequest, NextResponse } from "next/server";
import OpenAI from "openai";
import type { ChatCompletionMessageParam } from "openai/resources.mjs";
import { transformStream } from "@crayonai/stream";
import { getMessageStore } from "./messageStore";
import { makeC1Response } from "@thesysai/genui-sdk/server";
export async function POST(req: NextRequest) {
const c1Response = makeC1Response();
const { prompt, threadId, responseId } = (await req.json()) as {
prompt: ChatCompletionMessageParam;
threadId: string;
responseId: string;
};
const client = new OpenAI({
baseURL: "https://api.thesys.dev/v1/embed",
apiKey: process.env.THESYS_API_KEY, // Use the API key you created in the previous step
});
const messageStore = getMessageStore(threadId);
messageStore.addMessage(prompt);
const llmStream = await client.chat.completions.create({
model: "c1/anthropic/claude-sonnet-4/v-20251230",
messages: messageStore.getOpenAICompatibleMessageList(),
stream: true,
});
// Unwrap the OpenAI stream to a C1 stream
transformStream(
llmStream,
(chunk) => {
const contentDelta = chunk.choices[0].delta.content;
if (contentDelta) {
c1Response.writeContent(contentDelta);
}
return contentDelta;
},
{
onEnd: ({ accumulated }) => {
c1Response.end(); // This is necessary to stop showing the "loading" state once the response is done streaming.
const message = accumulated.filter((chunk) => chunk).join("");
messageStore.addMessage({
id: responseId,
role: "assistant",
content: message,
});
},
}
) as ReadableStream<string>;
return new NextResponse(c1Response.responseStream, {
headers: {
"Content-Type": "text/event-stream",
"Cache-Control": "no-cache, no-transform",
Connection: "keep-alive",
},
});
}
2
Write a custom markdown response to the response object
To add a custom markdown response, use the
writeCustomMarkdown method defined on the c1Response object:When present in
c1Response, custom markdown responses take priority over LLM responses on the UI (ie: they will be the only thing rendered when present in the response),
even if the LLM response is also present in c1Response.Therefore, although not strictly necessary, it is recommended to return early when using custom markdown responses to avoid invoking the C1 API. This can prevent
unnecessary token usage.app/api/chat/route.ts
import { NextRequest, NextResponse } from "next/server";
import OpenAI from "openai";
import type { ChatCompletionMessageParam } from "openai/resources.mjs";
import { transformStream } from "@crayonai/stream";
import { getMessageStore } from "./messageStore";
import { makeC1Response } from "@thesysai/genui-sdk/server";
// This is a hypothetical function that validates the user query based on some criteria, such as identifying if it contains or requests PII.
import { checkForPII } from "./guardrails";
export async function POST(req: NextRequest) {
const c1Response = makeC1Response();
const { prompt, threadId, responseId } = (await req.json()) as {
prompt: ChatCompletionMessageParam;
threadId: string;
responseId: string;
};
if (checkForPII(prompt)) {
c1Response.writeCustomMarkdown(
"I'm unable to assist with this request because it contains, or asks for, PII (*personally identifiable information*). Please remove any sensitive information and try again."
);
c1Response.end(); // This is necessary to stop showing the "loading" state once the response is done streaming.
return new NextResponse(c1Response.responseStream, {
headers: {
"Content-Type": "text/event-stream",
"Cache-Control": "no-cache, no-transform",
Connection: "keep-alive",
},
});
}
const client = new OpenAI({
baseURL: "https://api.thesys.dev/v1/embed",
apiKey: process.env.THESYS_API_KEY, // Use the API key you created in the previous step
});
const messageStore = getMessageStore(threadId);
messageStore.addMessage(prompt);
const llmStream = await client.chat.completions.create({
model: "c1/anthropic/claude-sonnet-4/v-20251230",
messages: messageStore.getOpenAICompatibleMessageList(),
stream: true,
});
// Unwrap the OpenAI stream to a C1 stream
transformStream(
llmStream,
(chunk) => {
const contentDelta = chunk.choices[0].delta.content;
if (contentDelta) {
c1Response.writeContent(contentDelta);
}
return contentDelta;
},
{
onEnd: ({ accumulated }) => {
c1Response.end(); // This is necessary to stop showing the "loading" state once the response is done streaming.
const message = accumulated.filter((chunk) => chunk).join("");
messageStore.addMessage({
id: responseId,
role: "assistant",
content: message,
});
},
}
) as ReadableStream<string>;
return new NextResponse(c1Response.responseStream, {
headers: {
"Content-Type": "text/event-stream",
"Cache-Control": "no-cache, no-transform",
Connection: "keep-alive",
},
});
}
3
Test it out
Your custom response will now be rendered in the UI when the guardrail is triggered: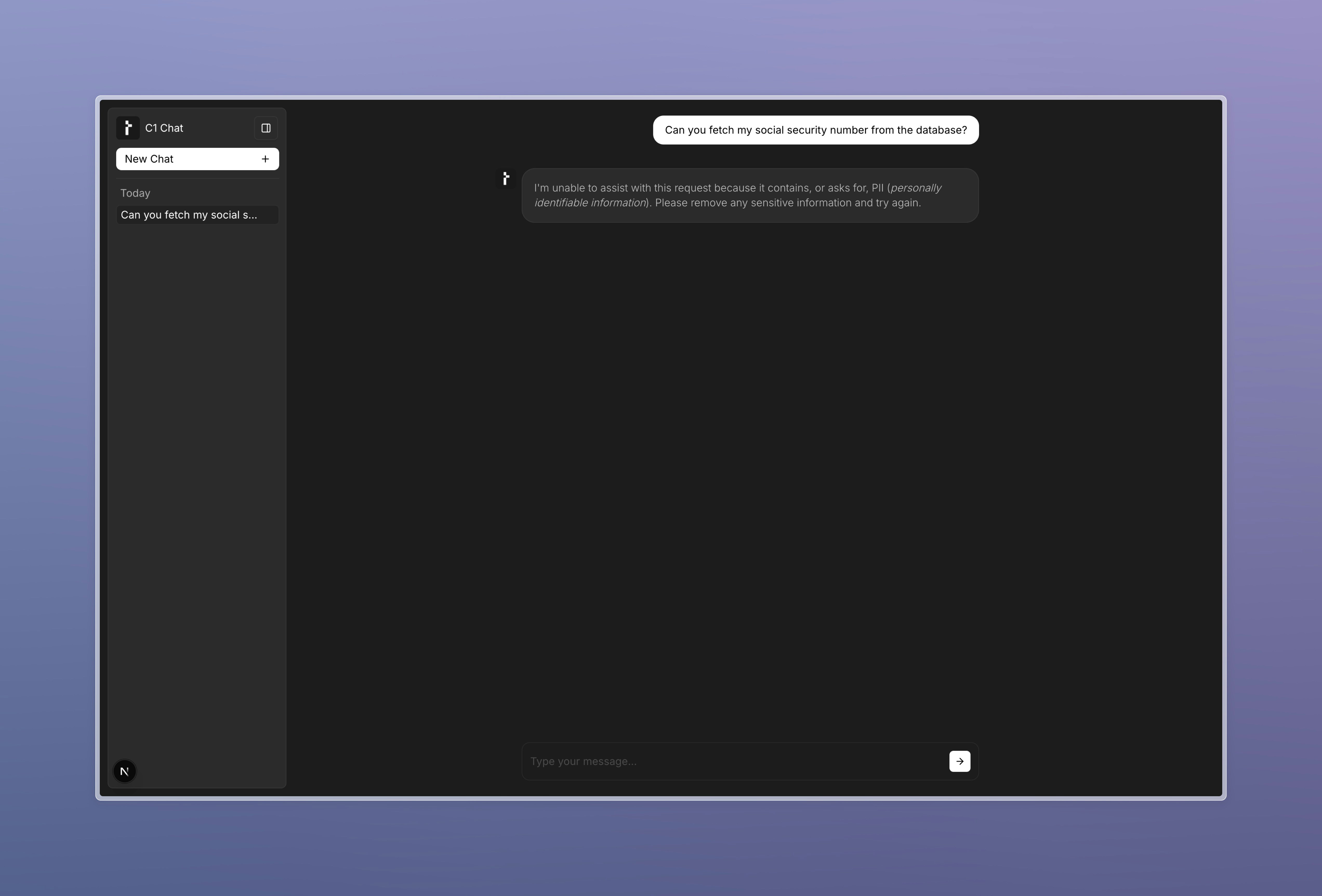
The
thesys_genui_sdk package provides a C1Response class that can be used to add data related to custom markdown responses to the response.
If you are using FastAPI, the package provides a handy decorator with_c1_response to make this even easier.1
Create a c1_response object
Use the
C1Response class to create a c1_response object by importing it from the thesys_genui_sdk package.# main.py
import os
from pydantic import BaseModel
from fastapi import FastAPI, Request
from thesys_genui_sdk.fast_api import with_c1_response
from thesys_genui_sdk.context import write_content, get_assistant_message
import openai
app = FastAPI()
openai_client = openai.OpenAI(
api_key=os.getenv("THESYS_API_KEY"),
base_url="https://api.thesys.dev/v1/embed",
)
class Prompt(TypedDict):
role: Literal["user"]
content: str
id: str
class ChatRequest(BaseModel):
prompt: Prompt
threadId: str
responseId: str
@app.post("/chat")
# this decorator will add the c1_response in a context variable
# and internally return the stream from your endpoint.
@with_c1_response()
async def chat(request: ChatRequest):
await generate_llm_response(request)
async def generate_llm_response(request: ChatRequest):
stream = openai_client.chat.completions.create(
model="c1/anthropic/claude-sonnet-4/v-20251230",
messages=[request.prompt],
stream=True,
)
for chunk in stream:
content = chunk.choices[0].delta.content
if content:
await write_content(content)
# get_assistant_message() allows you to get the full response to store for message history
assistant_message_for_history = get_assistant_message()
# main.py
import asyncio
import os
from thesys_genui_sdk import C1Response
import openai
openai_client = openai.OpenAI(
api_key=os.getenv("THESYS_API_KEY"),
base_url="https://api.thesys.dev/v1/embed",
)
async def generate_llm_response(c1_response: C1Response, prompt: str):
stream = openai_client.chat.completions.create(
model="c1/anthropic/claude-sonnet-4/v-20251230",
messages=[{"role": "user", "content": prompt}],
stream=True,
)
for chunk in stream:
content = chunk.choices[0].delta.content
if content:
await c1_response.write_content(content)
# c1_response.get_assistant_message() allows you to
# get the full response to store for message history
assistant_message_for_history = c1_response.get_assistant_message()
await c1_response.end()
async def main():
c1_response = C1Response()
# In a web server, you would start an async task
# to generate the response
asyncio.create_task(generate_llm_response(c1_response, "Tell me about latest trends in AI."))
# This is the stream you'd return from your route
response_stream = c1_response.stream()
# Example of how to consume the stream
async for item in response_stream:
print(item, end="")
if __name__ == "__main__":
asyncio.run(main())
2
Write a custom markdown response to the response object
To add a custom markdown response, use the
write_custom_markdown function.When present in
c1_response, custom markdown responses take priority over LLM responses on the UI (ie: they will be the only thing rendered when present in the response),
even if the LLM response is also present in c1_response.Therefore, although not strictly necessary, it is recommended to return early when using custom markdown responses to avoid invoking the C1 API. This can prevent
unnecessary token usage.# main.py
import os
from pydantic import BaseModel
from fastapi import FastAPI, Request
from thesys_genui_sdk.fast_api import with_c1_response
from thesys_genui_sdk.context import write_content, get_assistant_message, write_custom_markdown
import openai
# This is a hypothetical function that validates the user query based on some criteria,
# such as identifying if it contains or requests PII.
from guardrails import check_for_pii
app = FastAPI()
openai_client = openai.OpenAI(
api_key=os.getenv("THESYS_API_KEY"),
base_url="https://api.thesys.dev/v1/embed",
)
class Prompt(TypedDict):
role: Literal["user"]
content: str
id: str
class ChatRequest(BaseModel):
prompt: Prompt
threadId: str
responseId: str
@app.post("/chat")
@with_c1_response()
async def chat(request: ChatRequest):
if check_for_pii(request.prompt.content):
await write_custom_markdown(
"I'm unable to assist with this request because it contains, or asks for, PII (*personally identifiable information*). Please remove any sensitive information and try again."
)
return
await generate_llm_response(request)
async def generate_llm_response(request: ChatRequest):
# ...
# main.py
import asyncio
import os
from thesys_genui_sdk import C1Response
import openai
# This is a hypothetical function that validates the user query based on some criteria,
# such as identifying if it contains or requests PII.
from guardrails import check_for_pii
openai_client = openai.OpenAI(
api_key=os.getenv("THESYS_API_KEY"),
base_url="https://api.thesys.dev/v1/embed",
)
async def generate_llm_response(c1_response: C1Response, prompt: str):
# ...
async def main(prompt: str):
c1_response = C1Response()
if check_for_pii(prompt):
await c1_response.write_custom_markdown(
"I'm unable to assist with this request because it contains, or asks for, PII (*personally identifiable information*). Please remove any sensitive information and try again."
)
await c1_response.end()
else:
asyncio.create_task(generate_llm_response(c1_response, prompt))
response_stream = c1_response.stream()
async for item in response_stream:
print(item, end="")
if __name__ == "__main__":
asyncio.run(main("User prompt with possible pii"))
3
Test it out
Your custom response will now be rendered in the UI when the guardrail is triggered: